Cookbook: Vercel AI SDK (JS/TS)
This is a cookbook with an end-to-end example on how to use Langfuse Tracing (opens in a new tab) together with the Vercel AI SDK (opens in a new tab).
Vercel AI SDK capabilities (from the docs)
- React Server Components API for streaming Generative UI
- SWR-powered React, Svelte, Vue and Solid helpers for streaming text responses and building chat and completion UIs
- First-class support for LangChain and OpenAI, Anthropic, Cohere, Hugging Face, Fireworks and Replicate
- Node.js, Serverless, and Edge Runtime support
- Callbacks for saving completed streaming responses to a database (in the same request)
In this end-to-end example, we use the stream-lifecycle callbacks (opens in a new tab) to log all LLM calls to Langfuse via the Langfuse TS SDK (opens in a new tab). It also supports Node.js, Serverless, and Edge Runtimes and intgrates well with Langchain JS (integration docs (opens in a new tab)).
Hint: this is a deno-notebook and uses deno imports.
Backend API Route
Setup
Initialize Langfuse with your API keys from the project settings in the Langfuse UI. As we will use OpenAI LLMs for this example, we also want to configure an OpenAI client.
import { Langfuse } from "npm:langfuse"
import { Configuration, OpenAIApi } from "npm:openai-edge";
const langfuse = new Langfuse({
publicKey: "",
secretKey: "",
baseUrl: "https://cloud.langfuse.com",
});
const openAIconfig = new Configuration({
apiKey: "",
});
const openai = new OpenAIApi(openAIconfig);Cookbook-only: Add prompt to Langfuse
We'll also use Langfuse Prompt Management (opens in a new tab) in this example. To be able to subsequently pull a production prompt from Langfuse, we'll quickly push one to Langfuse.
If you copy and paste this example, consider creating the prompt one-off or via the Langfuse UI before moving to prod. Alternatively, you can hardcode your prompts and avoid using Langfuse Prompt Management.
await langfuse.createPrompt({
name: "qa-prompt",
prompt: "You are an extremely helpful assistant. Please assume that the person asking you questions needs your support and is totally honest with you.",
isActive: true // immediately promote to production
})API handler
The ai package provides a number of interfaces and abstractions.
In our example, we will use OpenAIStream to efficiently process and stream responses from OpenAI's models, and StreamingTextResponse to seamlessly deliver these AI-generated responses as HTTP streams to users.
import { OpenAIStream, StreamingTextResponse } from "npm:ai";Include the following if you deploy via Vercel:
// select edge rutime for low latency
export const runtime = 'edge';Main API handler.
/**
* Example application simulating a QA chat bot using Langfuse and Vercel AI framework.
*
* Creates trace, retrieves a pre-saved prompt template, generates answer, and scores generation.
* Utilizes OpenAI API for chat completion.
*
* @param {Request} req - The request object, containing session information, user ID, and messages.
* @param {Response} res - The response object used to send back the processed data.
* @returns {StreamingTextResponse} - A streamed response containing the output of the OpenAI model.
*/
export default async function handler(req: Request, res: Response) {
// initialize Langfuse
const trace = langfuse.trace({
name: "QA",
// Langfuse session tracking: https://langfuse.com/docs/tracing-features/sessions
sessionId: req.sessionId,
// Langfuse user tracking: https://langfuse.com/docs/tracing-features/users
userId: req.userId,
// Make public, so everyone can view it via its URL (for this demo)
public: true
});
// Format incoming messages for OpenAI API
const messages = req.messages
const openAiMessages = messages.map(({ content, role }) => ({
content,
role: role,
}));
// get last message
const sanitizedQuery = messages[messages.length - 1].content.trim();
trace.update({
input: sanitizedQuery,
});
const promptName = req.promptName
const promptSpan = trace.span({
name: "fetch-prompt-from-langfuse",
input: {
promptName,
},
});
// retrieve Langfuse prompt template with promptName
const prompt = await langfuse.getPrompt(promptName);
const promptTemplate = prompt.prompt
promptSpan.end({
output: {
promptTemplate,
},
});
// merge prompt template and user input
const assembledMessages = [
{
role: "system",
content: promptTemplate,
},
...openAiMessages,
];
const generation = trace.generation({
name: "generation",
input: assembledMessages,
model: "gpt-3.5-turbo",
prompt, // link to prompt version from Langfuse prompt management
});
const response = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
stream: true,
messages: assembledMessages,
});
// Stream the response from OpenAI
const stream = OpenAIStream(response, {
onStart: () => {
// Add completionStartTime timestamp to be able to break down latency
// into delay until first token and the streaming duration
generation.update({
completionStartTime: new Date(),
});
},
onCompletion: async (completion) => {
generation.end({
output: completion,
// Conditionally log a warning state
level: completion.includes("I don't know how to help with that")
? "WARNING"
: "DEFAULT",
statusMessage: completion.includes("I don't know how to help with that")
? "Refused to answer"
: undefined,
});
// Score generation, assume these answers are all correct
if (!completion.includes("I don't know how to help with that")) {
generation.score({
name: "quality",
value: 1,
comment: "Factually correct",
});
}
trace.update({
output: completion,
});
// Make sure all events are successifully send to Langfuse
// before the stream terminates.
await langfuse.shutdownAsync();
},
});
// The AI package makes it super easy to add metadata as headers
// It is a bit hacky, but we can e.g. pass the TraceURL to the frontend
return new StreamingTextResponse(stream, {
headers: {
"X-Langfuse-Trace-Url": trace.getTraceUrl()
},
});
}Our Frontend
If you use React, you'll probably want to use the ai package's React hooks for state management and to consume the streamed response. Learn more here: https://sdk.vercel.ai/docs/getting-started#wire-up-a-ui (opens in a new tab)
To fit this into a notebook, we'll just call the API route directly.
// sample request to test handler function
const mockRequest = {
"sessionId": "testSession",
"userId": "testUser",
"promptName": "qa-prompt",
"messages": [
{
"role": "user",
"content": "What is love?"
},
]
}const response = await handler(mockRequest);
const data = await response.text();
console.log(data);Love is a complex and deep emotion that can manifest in various forms such as romantic love, platonic love, familial love, and love for oneself. It often involves feelings of care, affection, empathy, and a strong bond with another person. Love can bring joy, happiness, and fulfillment to our lives, but it can also be challenging and require effort, communication, and understanding to maintain healthy relationships. Overall, love is a fundamental aspect of human experience that can bring meaning and purpose to our lives.Explore the trace in the UI
Since we passed the trace url to the frontend via the http header and made it public, we cann access it on the Response object.
console.log(response.headers.get("X-Langfuse-Trace-Url"))https://cloud.langfuse.com/trace/14cd44b6-1a56-46af-ba85-3fd91bbf9739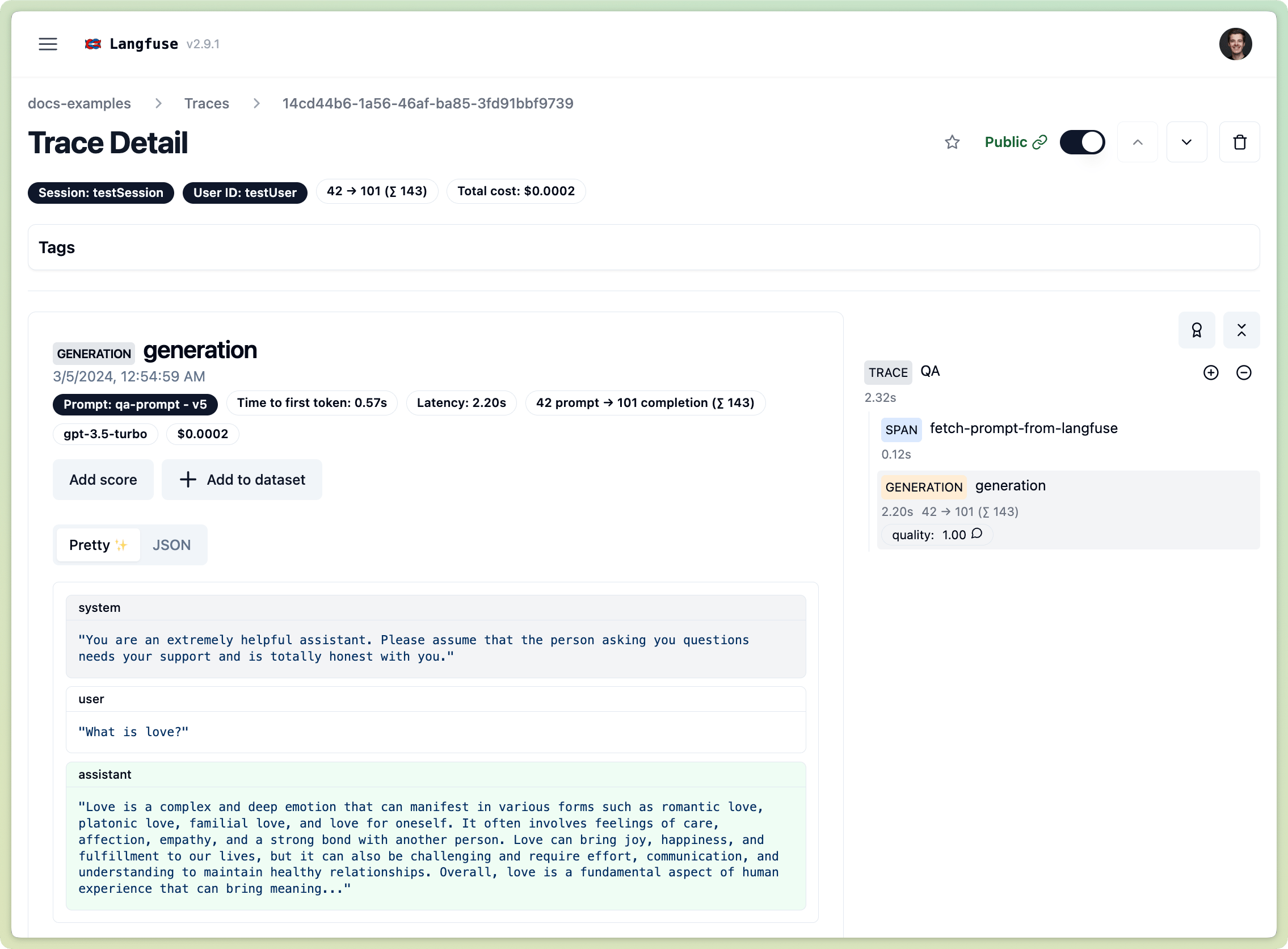
PS: As I ran this notebook a couple of times while putting it together, you can find a public session (opens in a new tab) view of me asking the same question What is love? here (opens in a new tab).
Production Demo
We also use the Vercel AI SDK to power the public demo (Docs Q&A Chatbot (opens in a new tab)). It's open source, see the full backend route here: qa-chatbot.ts (opens in a new tab).